
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion. . Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale..
What You Need To Know About Meta S Llama 2 Model Deepgram
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Open Foundation and Fine-Tuned Chat Models In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging. Today were introducing the availability of Llama 2 the next generation of our open source large language model Llama 2 is free for research and commercial use. Please review the research paper and model cards llama 2 model card llama 1 model card for more differences Discover more about Llama 2 here click through our. One such model is Llama 2 an open-source pre-trained model released by Meta which has garnered significant attention among early adopters..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large. Open Foundation and Fine-Tuned Chat Models This work develops and releases Llama 2 a. . In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2. Open Foundation and Fine-Tuned Chat Models In this. Pretraining Finetuning Safety Scaling up on both data and compute training strong base models to improve knowledge of..

Llama 2 Model Sizes 7b 13b 70b
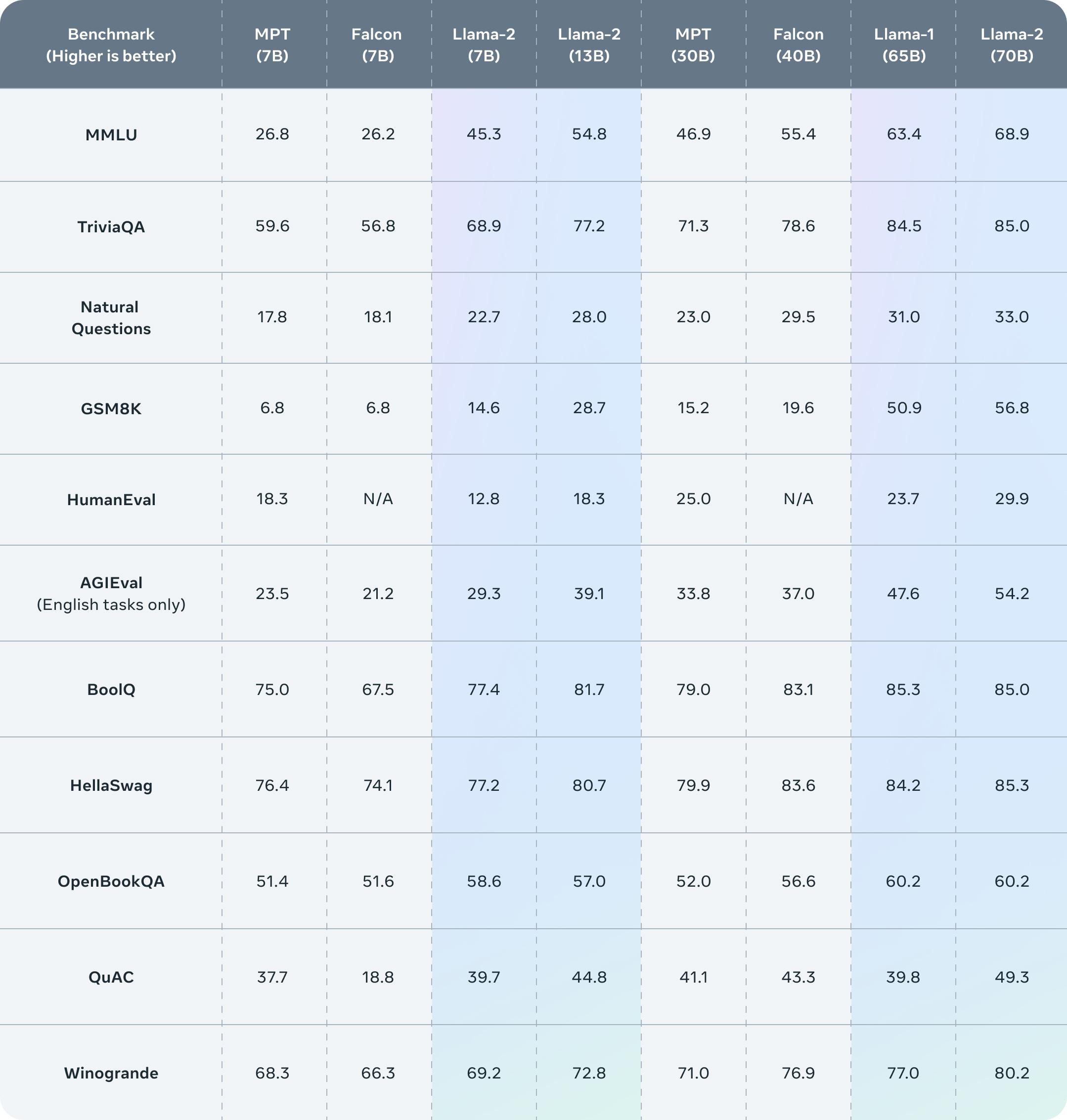
LLaMA v2 MMLU 34B at 626 and 70B now at 689 It seems like due to the x2 in tokens 2T the MMLU performance also moves up 1 spot Ie 7B now performs at old 13B etc. Llama 2 download links have been added to the wiki If youre new to the sub and Llama please see the stickied post below for. 1 Share uOptimal_Original_815 6 days ago LLaMA2 Training Has anyone trained LLaMA2 to respond with JSON data for a QA task The idea is to familiarize llama2 with domain specific Json. Llama2 torrent links While HuggingFaceco uses git-lfs for downloading and is graciously offering free downloads for such large files at times this can be slow - especially in. I wanted to play with Llama 2 right after its release yesterday but it took me 4 hours to download all 331GB of the 6 models If you dont have 4 hours or 331GB to spare I brought all the..




Komentar